For my English-speaking readers: This is a German article, which is due to the fact that the results I uncovered during the following analysis are mainly interesting for a German speaking audience. However, since the analytical method might be interesting for other contexts as well, I will be translating this article into English soon and share a link to it here.
Die Wahl zum 20. Deutschen Bundestag am 26. September 2021 wurde von vielen Beobachter*innen als besonders spannend und offen bewertet. Das lag zum einen daran, dass die langjährige Kanzlerin, Angela Merkel, nach vier Legislaturperioden und 16 Jahren im Amt angekündigt hatte, nicht mehr kandidieren zu wollen. Zum anderen lag es daran, dass keiner der aussichtsreichen Parteien – CDU, SPD und erstmals Bündnis 90/Die Grünen – ein deutlicher Vorsprung zugemutet wurde. Der designierte Nachfolger Angela Merkels, Armin Laschet (CDU), hatte während des Wahlkampfes mit zahlreichen PR-Desastern zu kämpfen; die Sozialdemokraten galten nach 12 Jahren Große Koalition als ausgebrannt; und die Grünen erlebten nach einem regelrechten Höhenflug zu Beginn des Wahlkampfes einen Absturz. Kurzum: alles war offen.
In einer solchen Atmosphäre gewinnen Absichtserklärungen wie Wahlprogramme und nun – zwei Monate nach der Wahl – der Koalitionsvertrag zwischen SPD, Grünen und FDP an Bedeutung. Nach langen Verhandlungen veröffentlichten die drei Parteien am 24. November ein 178-Seiten starkes Dokument, in welchem sie ihre Vorhaben erklärten. Während der Koalitionsverhandlungen wurden immer wieder einzelne Informationen durchgestochen. Viele der Informationen deuteten darauf hin, dass die FDP öfter in der Lage gewesen ist, ihre eigenen Forderungen durchzusetzen, als die anderen beiden Parteien. Das alleine sollte stutzig machen, da die FDP mit rund 11,5 % deutlich schlechter abschnitt als die SPD (25,7 %) oder Bündnis 90/Die Grünen (14,8 %).
Als also der Koalitionsvertrag schlussendlich am 24. November veröffentlicht wurde, stellte ich mir die Frage: Wessen Handschrift trägt er eigentlich? Wer hat den Koalitionsvertrag maßgeblich geschrieben? Noch am selben Abend habe ich mich für rund drei Stunden vor den Rechner gesetzt und den Koalitionsvertrag einmal durch ein neuronales Netzwerk gejagt. Genauer gesagt handelte es sich um ein Long Short-Term Memory (LSTM). Die Aufgabe dieses Netzwerkes war es, die mutmaßlichen Autorinnen der einzelnen Sätze des Koalitionsprogrammes vorherzusagen, sodass ich quantifizieren konnte, welche Teile des Koalitionsvertrages von wem geschrieben wurden.
Das erste Ergebnis habe ich noch am selben Abend via Twitter verbreitet (Link zum Tweet) und eine folgende, etwas besser ausgearbeitete Analyse versprochen, die ich mit diesem Artikel nun endlich liefere:
Ich habe mal ein KI-System (ein sog. LSTM-Modell) über den #Koalitionsvertrag gejagd und geschaut: Wieviele Sätze (insgesamt 3.212) stammen eigentlich (sprachlich) aus wessen Feder? Das Ergebnis:
— Hendrik Erz (@sahiralsaid) November 24, 2021
FDP @fdp: 1.261
Grüne @Die_Gruenen: 1.118
SPD @spdbt: 833 pic.twitter.com/G0j64aeoq0
Der Koalitionsvertrag in Zahlen
Zunächst zu den deskriptiven Statistiken des Koalitionsvertrages: Es handelt sich um ein 178-Seiten starkes PDF-Dokument mit 3.212 Sätzen und 51.638 Worten (12.699 einzigartige Wörter). Für die Datenanalyse habe ich durchgängig Python 3 verwendet. Methodisch war ich vor allen Dingen an zwei Ergebnissen interessiert: Was steht im Koalitionsvertrag? Und wer hat ihn geschrieben?
Ein Koalitionsvertrag ist trotz des Namens zuallererst eine Absichtserklärung und kein rechtlich bindendes Dokument. Außerdem ist ein Koalitionsvertrag immer auch eine Kommunikationsstrategie an die Bevölkerung, die vor allen Dingen versucht, die Wahlversprechen zu wiederholen. Ich habe mich hier theoretisch vor allem an Roberto Franzosi (2010) orientiert, welcher bereits vor über dreißig Jahren beschrieb, dass sich Handeln sprachlich auch in der grammatikalischen Struktur von Sprache widerspiegelt (vgl. auch John Mohr, 1998).
Dementsprechend war mein erstes Interesse, zu erfahren, was die Koalitionsparteien denn nun vorhaben. Mittels des Python-Paketes stanza habe ich die Grammatik aus den Sätzen des Koalitionsvertrages extrahiert. Stanza ist ebenfalls ein neuronales Netzwerk, entwickelt von der NLP Group der Stanford-Universität. Für weitere Informationen bezüglich des genauen Prozederes möchte ich hier auf das GitHub-Repository verweisen, wo ich den Code für die Analyse öffentlich gemacht habe.
Nachdem Stanza die Grammatik extrahiert hat, habe ich alle Subjekte, Verben und Objekte gesammelt und ihre Häufigkeit gemessen. Da Worte sowohl groß als auch klein geschrieben werden können (“wir”, “die”, “sie”), habe ich die Worte allesamt zu Kleinbuchstaben konvertiert.
Das Ergebnis — die häufigsten 20 Worte pro Kategorie — ist in Grafik 1 zu sehen:
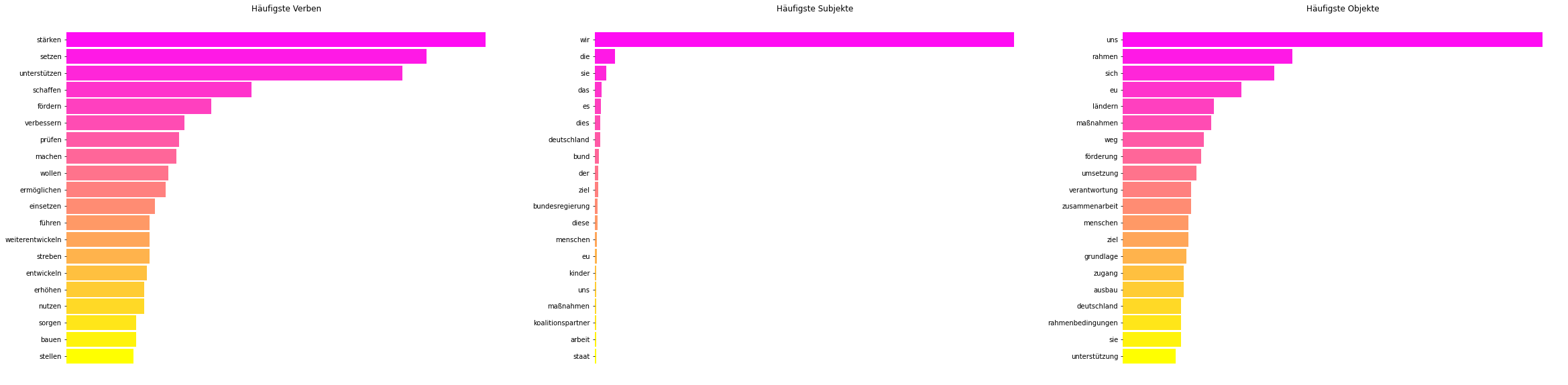
Was direkt auffällt ist eine dezidiert “politische” Sprache. Würden wir Sätze aus den Top 3-Einträgen bilden, kämen “Wir stärken uns”, “Die setzen Rahmen” und “Sie unterstützen sich” heraus. Es wird deutlich, dass vor allem unterstützende Verben genutzt wurden: Man möchte etwas stärken, vielleicht eine Agenda (?) setzen und viel unterstützen. Die Wortwahl deutet darauf hin, dass nicht die Koalitionsparteien selbst Projekte initiieren wollen, sondern vor allem andere Akteure etwas tun sollen, welche die Regierung dann darin stärken, unterstützen oder fördern möchte.
Weniger divers ist die Wahl der Subjekte. Es gibt genau ein Subjekt, und das ist die Koalition: “Wir” wollen etwas tun. “Deutschland” als Ganzes nur relativ selten, genauso wie die “Bundesregierung”. Die “EU” taucht als handelndes Subjekt auch kaum auf. Sehr spannend ist aber auch, für wen sie etwas machen. Wen wollen “wir” stärken, unterstützen, fördern, oder verbessern? Sehr sehr oft sich selbst. Hier sollten wir aber auch vorsichtig sein, denn es ist davon auszugehen, dass die Koalitionäre auch passive Sprache verwendet haben. Der Satz “Wir wollen Deutschland stärken” ist äquivalent zu “Deutschland wird von uns gestärkt”, allerdings ist einmal “Wir” das Subjekt und einmal “Deutschland” – nur in einer passiven Formulierung. Durch passive Sprache kann gewissermaßen die Agenz umgedreht werden und das Objekt macht etwas mit dem Subjekt.
Von wem stammt der Koalitionsvertrag? Akteurszentrierte Analyse
Kommen wir nun aber zum “Highlight” dieser Analyse, welches auf Twitter bereits einiges an Aufmerksamkeit bekommen hat: Die Frage “wer hat was geschrieben?” Die grundlegenden Annahmen dieses Teils der Analyse habe ich auf Twitter naturgemäß nicht ausgeführt, daher soll das hier nachgeholt werden.
Zunächst gehe ich davon aus, dass der Koalitionsvertrag eine Teilmenge der Wahlprogramme der einzelnen Parteien ist: Was nicht in den Wahlprogrammen steht, wird sehr wahrscheinlich auch im Koalitionsvertrag nicht auftauchen. Umgekehrt werden allerdings einige Dinge nicht im Koalitionsvertrag auftauchen, die in einzelnen Wahlprogrammen zu finden sind.
Eine zweite Annahme ist, dass die Verfasser*innen des Koalitionsvertrages mutmaßlich nur wenige Sätze völlig neu erfunden haben. Im politischen Bereich wird teils heftig um Formulierungen gestritten, und so wäre es nicht verwunderlich, wenn bestimmte Formulierungen aus den Programmen auch hier auftauchen.
Zuletzt gehe ich davon aus, dass um jeden Satz gestritten wird und somit jeder Satz ein einzelnes Verhandlungsergebnis darstellt. Das bedeutet, dass wir auf Ebene einzelner Sätze herausfinden können, wer sie zu verantworten hat.
Diese Annahmen habe ich wie folgt operationalisiert: Die Nullhypothese1 ist, dass alle drei Parteien exakt gleich viel zum Koalitionsvertrag beigetragen haben. Die unabhängigen Variablen2 sind sowohl die konkreten Worte, welche verwendet wurden, als auch die Grammatik (Formulierungen). Die abhängige Variable ($Y$) in diesem Fall war die Autorin, d.h. die Partei, welche den entsprechenden Satz mutmaßlich verfasst hat.
Ich bin mit diesen Annahmen wie folgt vorgegangen: Zunächst habe ich die drei Wahlprogramme der entsprechenden Parteien heruntergeladen und den Text daraus extrahiert. Diesen Rohtext habe ich weiter bearbeitet, indem ich zunächst Kopf- und Fußzeilen entfernt habe sowie bei der FDP zusätzlich Tabellen, die diese in den Text eingearbeitet hatte. Weiterhin habe ich die Silbentrennung rückgängig gemacht. Dann habe ich alle drei Wahlprogramme durch Stanza laufen lassen, sodass ich auch die grammatikalischen Informationen bekam und schlussendlich habe ich ein Trainings-Datenset erstellt, indem ich die gleiche Anzahl an Sätzen von allen drei Parteien in eine einzelne Datei geschrieben habe. Einen großen Teil des Grünen Wahlprogrammes musste ich daher verwerfen3. Ich habe die Satzreihenfolge randomisiert und dann aus allen drei Wahlprogrammen dieselbe Menge an Sätzen extrahiert. Hätte ich das grüne Wahlprogramm in Gänze verwendet, sähe die “Welt” des Klassifizierers so aus, dass die Grünen doppelt so viele Sätze geschrieben haben, wie die anderen beiden Parteien – ein bias, den ich vermeiden wollte.4
Schlussendlich habe ich einen LSTM-basierten Klassifizierer darauf trainiert, anhand eines Satzes dessen Autorin zu bestimmen. Anschließend habe ich den Klassifizierer alle Sätze des Koalitionsprogrammes bestimmen lassen. Die daraus resultierende Tabelle enthält folgende Informationen: Den eigentlichen Satz, die prozentuale Wahrscheinlichkeit, mit welcher er von einer der drei Parteien geschrieben wurde sowie – zur einfacheren Weiterverarbeitung – den Namen der Partei, von der der Satz am wahrscheinlichsten stammt.
Das Ergebnis dieser Bemühungen lässt sich kurz und bündig zusammenfassen: Am meisten geschrieben hat die FDP (1.261 Sätze), gefolgt von den Grünen (1.118 Sätze), und weit abgeschlagen die SPD (mit nur 833 Sätzen). Hätte der Koalitionsvertrag die Stimmverteilung widergespiegelt, hätten SPD und FDP eigentlich die Plätze tauschen müssen.
Wie kann das sein?
Warum so viel FDP?
Hierzu gibt es verschiedene Theorien. Eine mögliche Theorie ist die “Königsmacher”-Theorie: Die FDP hat bereits vor vier Jahren einmal eine Jamaica-Koalition platzen lassen mit dem berühmten Spruch “Lieber nicht regieren als falsch regieren”. Das bedeutet, dass die FDP einen erheblichen Verhandlungsvorteil hatte: Alle wussten, dass die FDP erneut hätte sagen können: “Okay, so lieber nicht, viel Spaß bei der weiteren Regierungsbildung!” Das hat ihr natürlich einen enormen Vorteil verschafft, da alle Parteien sich bemühen mussten, die FDP bei Laune zu halten.
Zudem habe ich erfahren, dass die SPD in den Koalitionsverhandlungen wohl eher müde gewesen sei und nur ihre wenigen zentralen Forderungen in das Dokument verfrachtet hat, und bei den weiteren Verhandlungen offenbar sehr lustlos war.
Aber wie sieht es denn mit den Überschneidungen aus zwischen den Parteien? Sind sich Grüne und FDP wirklich näher als der SPD? Laut der Daten: nein. Der durchschnittliche Abstand zwischen den einzelnen Parteien in den Vorhersagen ist wie folgt:
- Der durchschnittliche Unterschied zwischen den SPD und den Grünen beträgt 52 Prozentpunkte
- Der durchschnittliche Unterschied zwischen SPD und FDP beträgt 58 Prozentpunkte
- Der durchschnittliche Unterschied zwischen Grünen und FDP beträgt 63 Prozentpunkte
Um das etwas besser zu verstehen, hilft es, sich vor Augen zu führen, was der Klassifizierer macht. Zunächst können wir davon ausgehen, dass jeder Satz definitiv von einer der drei Parteien geschrieben worden ist. Das heißt, die Wahrscheinlichkeit, dass ein Satz von irgendeiner dieser Parteien stammt, ist 100 % oder $p(\text{Satz}|\text{FDP} \lor \text{SPD} \lor \text{B90}) = 1$. Der Klassifizierer vergibt also insgesamt 100 %, verteilt auf die drei Parteien. Wenn nun zwei Parteien dieselben Sätze schreiben würden, würde der Klassifizierer diesen Parteien dieselben Wahrscheinlichkeiten vergeben; der durchschnittliche Unterschied betrüge also null Prozent. Wir sehen also, dass rein sprachlich SPD und Grüne sich näher sind als beide Parteien der FDP.
Das bestärkt das Ergebnis von weiter oben, dass die FDP einen Großteil der Sätze verfasst hat (bzw. dass ein Großteil der Sätze besonders liberal klingen).
Die Top-Sätze der Parteien
Ein letztes Ergebnis, welches sich aus der Analyse ziehen lässt, sind die Sätze, bei denen sich der Klassifizierer ganz besonders sicher war, dass sie von einer der Parteien stammen. Ich füge diese Sätze hier ohne großartige Einordnung an und überlasse es den Leser*innen, sie zu interpretieren.
SPD5
- Wir wollen Europa zu einem Kontinent des nachhaltigen Fortschritts machen und international vorangehen.
- Die in anderen Bereichen bewährte Sicherheitsüberprüfung von Bewerberinnen und Bewerbern weiten wir aus und stärken so die Resilienz der Sicherheitsbehörden gegen demokratiefeindliche Einflüsse.
- Innovativen Materialien, Technologien und Start-ups wollen wir den Markteintritt und Zulassungen erleichtern.
- Wir werden dabei die Praxis und betroffene Kreise aus der Gesellschaft und Vertreterinnen und Vertreter des Parlaments besser einbinden sowie die Erfahrungen und Erfordernisse von Ländern und Kommunen bei der konkreten Gesetzesausführung berücksichtigen.
- Dazu beseitigen wir alle Hemmnisse, u. a. werden wir Netzanschlüsse und die Zertifizierung beschleunigen, Vergütungssätze anpassen, die Ausschreibungspflicht für große Dachanlagen und die Deckel prüfen.
- Wir ratifizieren das Übereinkommen Nr. 184 der Internationalen Arbeitsorganisation (ILO) über den Arbeitsschutz in der Landwirtschaft.
- Sozial gerechte Energiepreise Um – auch angesichts höherer CO2-Preiskomponenten – für sozial gerechte und für die Wirtschaft wettbewerbsfähige Energiepreise zu sorgen, werden wir die Finanzierung der EEG-Umlage über den Strompreis beenden.
- In den 2030er Jahren soll es ein einheitliches EU-Emissionshandelssystem über alle Sektoren geben, das Belastungen nicht einseitig zulasten der Verbraucherinnen und Verbraucher verschiebt.
- Dazu ist die Stärkung der Forschung an neuen nachhaltigen Batterie-Generationen entscheidend.
Bündnis 90/Die Grünen
- Hierfür werden wir die Beteiligungsmöglichkeiten von kleinen und mittleren Betrieben an Vergabeverfahren stärken.
- Wir machen aus technologischem auch gesellschaftlichen Fortschritt.
- Wir stärken die globale Gesundheitsarchitektur im Rahmen des One Health-Ansatzes.
- Vollständig an das Integrationsamt übermittelte Anträge gelten nach sechs Wochen ohne Bescheid als genehmigt (Genehmigungsfiktion).
- Friedliches Zusammenleben und Zusammenhalt in einer vielfältigen Gesellschaft erfordern, Unterschiede zu achten und divergierende Interessen konstruktiv auszuhandeln.
- Die EU muss international handlungsfähiger und einiger auftreten.
- Die natürliche CO2-Speicherfähigkeit der Meere werden wir durch ein gezieltes Aufbauprogramm verbessern (Seegras-Wiesen, Algenwälder).
- Wir bringen eine Exzellenzinitiative Berufliche Bildung auf den Weg, u. a. bauen wir InnoVet aus und öffnen die Begabtenförderungswerke des Bundes für die berufliche Bildung.
- Wir geben eine Machbarkeitsstudie in Auftrag um zu untersuchen, ob ein Grundbuch auf der Blockchain möglich und vorteilhaft ist.
- Krisenprävention und ziviles Krisenmanagement werden wir in besonderer Weise stärken, u. a. mehr ziviles Personal entsenden.
FDP
- Der privaten Pflegeversicherung würden wir vergleichbare Möglichkeiten geben.
- Den dezentralen Ausbau der Erneuerbaren Energien wollen wir stärken.
- Wir nehmen die Evaluation des Bundesteilhabegesetzes ernst und wollen, dass es auf allen staatlichen Ebenen und von allen Leistungserbringern konsequent und zügig umgesetzt wird.
- Wir schließen Lücken im Opferentschädigungsrecht und bei der Opferhilfe.
- Die bestehenden Förderprogramme für HAW bauen wir als zentrale Erfolgsfaktoren für die Agentur aus.
- Wir werden seniorengerechte Ansätze auf allen staatlichen Ebenen und im digitalen Raum fördern.
- Mobilität ist für uns ein zentraler Baustein der Daseinsvorsorge, Voraussetzung für gleichwertige Lebensverhältnisse und die Wettbewerbsfähigkeit des Wirtschafts- und Logistikstandorts Deutschland mit zukunftsfesten Arbeitsplätzen.
- Wir wollen unser Auslandsschulnetz und das PASCH-Netzwerk durch einen Masterplan weiterentwickeln, einen Schulentwicklungsfonds auflegen, frühkindliche Bildung, Inklusion und die Schulleitungen stärken.
- Drittens brauchen wir einen neuen Schub für berufliche Aus-, Fort- und Weiterbildung oder Neuorientierung auch in der Mitte des Erwerbslebens, vor allem dann, wenn der technologische Wandel dies erfordert.
- Unser Ziel ist eine souveräne EU als starker Akteur in einer von Unsicherheit und Systemkonkurrenz geprägten Welt.
Diskussion
Was bleibt von diesem Experiment? Zunächst konnte ich zeigen, dass der Koalitionsvertrag deutlich die Handschrift der Liberalen trägt, obgleich sich Grüne und SPD ähnlicher sind als der FDP. Das heißt, falls sich alle Regierungsparteien in den kommenden vier Jahren stoisch an den Koalitionsvertrag halten sollten, werden wir in vier Jahren in einem deutlich neoliberaleren Land leben – was ich persönlich nicht hoffe.
Allerdings ist die einfachste Erklärung schlicht jene: Die FDP wollte möglichst viele ihrer Forderungen im Vertrag sehen, die SPD nicht. Doch da die SPD die meisten Abgeordneten stellt, hat die SPD ungeachtet des Koalitionsvertrages noch viele Möglichkeiten, Forderungen der FDP umzuwerfen, abzuändern oder mehr eigene Punkte im Verlauf der nächsten vier Jahre umzusetzen. Kurzum: Die SPD ist nicht auf den Koalitionsvertrag angewiesen. Umgekehrt wird die FDP hoffen, dass sie, wann immer sie etwas durchsetzen möchte, auf den Koalitionsvertrag zeigen kann.
In jedem Fall: Was sich an den Ergebnissen zeigt ist, dass das, was von internationalen Firmen gerne mit magischem Klang unter dem Deckmantel “Künstliche Intelligenz” verkauft wird, bei weitem nicht so großartig ist, wie es verkauft wird. Aber es hat sehr gute und hilfreiche Einsatzszenarien – wenn man denn weiß, was man tut.
In den nächsten drei Jahren werde ich im Rahmen meiner Doktorarbeit hoffentlich zeigen können, was noch alles möglich ist mit solchen Klassifizierern – abseits von Koalitionsspielereien. Doch dazu später – dann wieder auf Englisch – mehr auf diesem Blog!
Abschließende Bemerkungen
Auf Twitter hat sich nach meinem Ursprungstweet ein User gemeldet und moniert, dass die Datenmenge, welche ich zum Training des Netzwerkes verwendet habe, viel zu gering gewesen sei. Das stimmt. Die Wahlprogramme bilden nur einen kleinen Teil der möglichen Sätze aus den Reihen von SPD, FDP oder Bündnis 90/Die Grünen ab. Nichtsdestotrotz denke ich, dass die Verwendung des LSTMs hier korrekt war. Mit zu wenigen Daten kann ein solches Modell von Sprache natürlich nicht generalisieren, d.h. es wird schwierig, völlig andere Sätze einzuordnen. Dieses Modell lässt sich nicht wie Google Translate für alle möglichen Zwecke verwenden.
Nichtsdestotrotz bin ich überzeugt, das LSTM hier artgerecht gehalten zu haben, denn: Ein gewisses “overfitting”6 ist in diesem Fall sogar gut, da ich ja nur an einem sehr kleinen, sehr begrenzten Problem interessiert war und – wie oben ausgeführt – so oder so kaum Varianz in den Daten zu vermuten gewesen ist.
Nun lässt sich einwenden, weshalb ich überhaupt ein LSTM verwendet habe und nicht etwa eine wesentlich simplere Methodik, beispielsweise ein Topic Model oder eine SVM (Support Vector Machine)? Der eine Hauptgrund ist, dass neuronale Sprachmodelle wie ein LSTM sehr robust gegenüber kleineren Fehlern sind und ich nicht Tage mit dem Aufräumen der Daten verbringen wollte. Ein LSTM zu erstellen ist tatsächlich schneller, als die Sätze in eine Form zu verfrachten, in der ein Topic Model damit etwas anfangen kann. Der andere Grund aber ist, dass ein LSTM anders als ein Topic Model auch minimale Unterschiede in Kontext und Grammatik (pragmatics und syntax) zur Unterscheidung der Parteien nutzen kann. Damit konnte ich sichergehen, dass auch schwer erkennbare Unterschiede im Schreibstil der einzelnen Parteien Einfluss auf das Modell hatten.
Referenzen
- Link zum öffentlichen Repository
- Franzosi, R. (2010). Quantitative narrative analysis. SAGE.
- Mohr, J. W. (1998). Measuring Meaning Structures. Annual Review of Sociology, 24, 345–370. https://doi.org/10.1146/annurev.soc.24.1.345
-
Die Nullhypothese ist die zu widerlegende Annahme. Das heißt, wenn ich daran interessiert bin, zu erfahren, ob eine Partei mehr als andere geschrieben hat, gehe ich vom Gegenteil aus; nämlich, dass alle Parteien genau gleich viel Anteil hatten. Sollte diese (Null)Hypothese nicht zutreffen, hatte ich mit meiner eigentlichen Vermutung Recht. ↩
-
Die unabhängigen Variablen sind Variablen, von denen wir ausgehen, dass sie sich nicht gegenseitig beeinflussen. Die abhängige Variable ist in der Analyse immer diejenige, die (laut unseren Hypothesen) durch die unabhängigen Variablen "verursacht" wird. ↩
-
Die Grünen hatten fast 300 Seiten Wahlprogramm, die anderen Parteien viel weniger. Ich habe auch keine Ahnung, wie die es geschafft haben, ihr Wahlprogramm derart aufzublähen. ↩
-
Um diesen Gedanken etwas auszuführen: Auch die vielgelobte "künstliche Intelligenz" ist nicht viel mehr als ein Haufen Statistik. Das heißt, dass auch KI die gleiche Achillesferse hat wie Statistik: Wenn ich dem Klassifizierer mehr Grüne Sätze gegeben hätte, als Sätze von FDP und SPD, dann wäre der Klassifizierer geneigt gewesen, entsprechend dieses Verhältnisses auch mehr Sätze als "grün" zu deklarieren, was aber nicht der Nullhypothese entsprochen hätte. ↩
-
Ein Satz aus der Top-10 der SPD war nur ein kleines Satzfragment, welches nicht interpretierbar war und ich daher entfernt habe. ↩
-
Overfitting, oder, "über das Ziel hinauszuschießen" bedeutet schlicht, dass der Klassifizierer zwar sehr gut die Trainingsdaten vorhersagen kann, aber sehr schlecht mit allen anderen Daten umgeht. Das Gegenteil zu overfitting ist underfitting, was bedeutet, dass dem Klassifizierer wichtige Informationen fehlen, die ihm das Vorhersagen der Trainingsdaten ermöglichen würden. ↩