Web scraping can be very frustrating. From wrong character sets through malformed HTML code, to weird and seemingly unexplainable behavior, there are many pitfalls for social scientists who need to construct a dataset based off information scattered around the net. The frustration is in the name: Instead of properly accessing the internet, you are scraping its surface. Many issues can be solved by understanding three crucial blocks on which web scraping builds: networking and software architecture, web design, and the web scrapers themselves.
The underlying software – including encoding strategies, compression, networking protocols like the TCP/IP-stack, and others – are a whole topic in itself, but thankfully are (mostly) handled for you by the accompanying web scraping libraries. The web scrapers are often ancient pieces of technology, but they work well, and to understand them, reading their accompanying manuals is sufficient. The big star of today’s article is web design.
Web design is usually connoted with self-taught entrepreneurs and marketing agencies. It evokes feelings of beautiful looking websites that are farther apart from our daily social scientific reality than the newest trend on TikTok. However, in order to facilitate creating beautifully looking websites, web designers need to use some technologies. And those technologies – including how they are used – are what we social scientists also need to understand when we need to scrape data from the web.
In this article, I want to provide some context on the technologies of the web and certain design patterns that you will come across when you have to scrape data. I want to give you some guidance to understand the sometimes very convoluted structures of websites, and how to navigate them to get to the actual data you are interested in. I want to show you what a web designer has thought when they have nested ten <div>-elements without any apparent purpose.
There are things that I will not go into. For example questions about centering Divs, creating a floating navbar, or anything like this. I will also not cover how to utilize the actual web scraping libraries in either R or Python here, since that is covered a lot elsewhere.
In other words, this article assumes that you have already a bit of experience with what web scraping does, and how it works. It will merely guide you through being more efficient when analyzing an HTML document in order to determine the corresponding XPaths or regular expressions that you need in order to extract the data you need. I will cover common conceptualizations of websites, design patterns, and structures that you will come across when scraping data.
The Purpose of Web Scraping
First, let us recapitulate the purpose of web scraping. In a perfect world, we wouldn’t need to scrape anything at all. Instead, we would just download a ready-made dataset. And that is the purpose of web scraping: Generating a dataset that does not yet exist, out of data that lies scattered across the internet. There are three levels of getting to your data:
- Simple: Your supervisor sends you a ready-made CSV file. That’s beautiful, you don’t have to do any data collection.
- Moderate: You’ll have to find a dataset online. This involves some research, but in the end you have a CSV that you can use to do your research.
- Hard: That’s what web scraping is all about: There is no data set, you have to painstakingly collect everything yourself. This is what this article is about.
However, it turns out that even if you can’t find a CSV file, any dataset you may want already exists out there. This may surprise you, but all the websites you visit daily are driven by a database that resembles those DataFrames of R or Python. So why is it a problem that we have to scrape data instead of just downloading the data?
Well, that database is ideally not accessible from the outside. Rather, there is a server in between you and the precious data, and you will have to work with the server to make it give that data to you.
The Anatomy of a Website
Some websites make it relatively painless to access data directly by providing so-called API access (Application Programming Interface). If a website has such an API, you won’t have to scrape anything at all. Instead, just call the API directly which will give you the data neatly formatted without you having to do anything special. The API will return the data often in JSON format, and every programming language nowadays has built-in support for JSON.
However, most websites that have data that we as social scientists are interested in don’t provide such an API. Why is that? Well, developing an API is difficult, and many website owners don’t want to, and need to go through the pain of offering such an API. The primary purpose of a website is to display some information in such a way that it is easy for us humans to read through it.1 There are many nuances to that which I won’t get into right now, but I hope you get the point.
Take this following diagram to get a sense of what I mean:
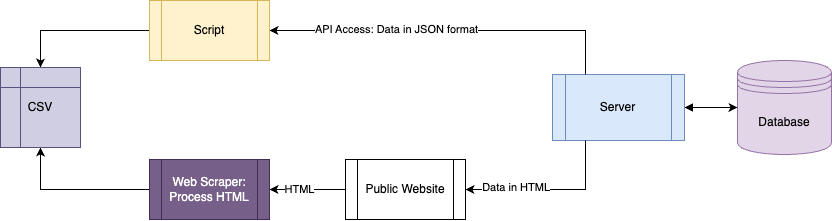
As you can see, whereas accessing an API directly is very simple and usually only takes two to three lines of code, when you need to access data via the “browser” route, it gets more complicated. The main issue is that most websites don’t have the upper path in the diagram, and you must take the bottom path.
Let’s begin by talking about what the server does to the neatly formatted data to make it so awkward to work with. Web scraping has to undo everything the server is doing. The server wraps the data into HTML elements, adds some CSS and maybe some JavaScript, and your web scraping script reverses all the work again.
In order to then reverse-engineer that specific process, you need to understand the web design behind it. There is more than one way to wrap tabular data, for example – in a list, as a table, or using CSS grids and flex-box layouts.
And that is precisely the purpose of this article: Understand the anatomy of a website so that you know what to look for to extract data without too much of a pain. The good news first: You won’t have to understand much of the CSS used for that. 80% of your work can be done with plain HTML.
Relevant Web Technologies
Crucially, there are three web technologies you must understand from a designer’s perspective to grasp the fundamentals of web scraping: HyperText Markup Language (HTML), Cascading Style Sheets (CSS), and JavaScript (JS). These web technologies relate as follows:
- HTML contains the actual content, the actual data that you want to use. It is often sent directly from the server, but with modern, dynamic websites, this may be loaded after the fact with JavaScript.
- CSS is exclusively used to style the content. There is not a single bit of actual information in there (with a few minor caveats, see below), so you can almost forget that it exists for web scraping purposes.
- JS is used to add interactivity to a website. There are two types of interactivity. The good type is when JavaScript is used to merely enhance a static website with some dynamics. In that case, JavaScript is nice to have, but you don’t have to account for it while scraping. It is bad, however, when you are dealing with a Single-Page Application (SPA) that loads everything dynamically from the server. Then, you suddenly have to deal with a private API.
But first things first. Let’s go through each of them individually and explain what they do.
HTML
HTML is the dinosaur among the web technologies. It was the first language for the internet, and to this day, it still makes up the biggest part of most websites. It is used to structure information in a tree. That tree is called the Document Object Model (DOM). It has a single root node, called document, and then everything else follows as children to that root. Each node (i.e., each tag), has a set of attributes, and finally some content, which can in itself be a node again, or just a string of text.
Each HTML document has the same basic structure:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Document</title>
</head>
<body>
</body>
</html>
The problems begin with what is contained within the body tags, which is where the actual content begins. There are some metadata tags in the head element that may be of interest, but these are relatively simple to understand. So let’s get into the actual HTML inside the <body>.
Semantic vs. Non-Semantic HTML
HTML can be written with two sets of tags, semantic tags and non-semantic tags. What’s the difference? Let us have a look at an example: A navigation bar. First, without semantic tags:
<div class="nav">
<a href="#">Home</a>
<a href="#">About</a>
<a href="#">Contact</a>
</div>
And now, with semantic tags:
<nav>
<ul>
<li><a href="#">Home</a></li>
<li><a href="#">About</a></li>
<li><a href="#">Contact</a></li>
</ul>
</nav>
How can you now tell whether something is a navigation? In the first example, you’d have to deal with the non-semantic <div>-elements. The semantic code, however, makes it easier, because in the second instance, the entire navigation is wrapped in its own tag: <nav>. That tag is “semantic” because its name already tells you something about its intended use. You wouldn’t use a <nav>-element to wrap some tabular data.
This is just an example, but in your endeavors you will come about horrible code that completely ignores semantic HTML and makes it extremely difficult to properly extract information from it. When a website uses semantic HTML, you will see it with the tags that it uses, and you should try to stick to those as much as possible. Everything can be styled to look like a navigation, but if a web designer uses the <nav>-tag, you can be pretty sure that it definitely contains just a navigation. Some tags’ uses are a bit more blurry, but with some common sense, you should be able to quickly spot the patterns the web designer used.
The tag names that you will come across most often will be <div> and <span>, however. They are the paradigmatic non-semantic tags. “Div” is short for “diverse” and is intended to be a block-container for various pieces of your website. They can literally contain everything, so looking out for divs will give you a hard time. The same applies for “spans”, which are inline-elements, i.e., they are meant to be used to wrap small spans of text into elements that can be individually styled.
“How Many Engineers Does it Take to Center a Div?”
To understand the heavy usage of <div> and <span>, let me introduce you to a long-running joke in the web developer community: The extreme difficulty of centering a div. Instead of some very basic fonts and colors, people at some point wanted to add more live to their websites. Soon, there were rounded borders, color gradients, and margins around all kinds of elements.
The problem, however, is that styling – with CSS – is sometimes a bit of arcane magic, and there are usually two ways of properly styling a website to your liking: the proper but hard way of finding the correct CSS rules, and the easy way where you just wrap everything into twenty divs. And that’s one of the reasons for why you will often encounter websites that look like this:
<div id="main-content">
<div class="container">
<div class="nav-wrapper">
<a href="#">Element</a>
<!-- More horrors -->
</div>
</div>
</div>
It turns out that, while nesting a ton of <div>-tags into each other results in horrible HTML, it makes many styling-tasks much easier than using the appropriate semantic element with the appropriate CSS rules. And when time is money, thinking becomes expensive.
This means that it can be very hard to find the information you need. Many things can be done with less HTML, but few web designers care about the amount of nested divs because most people won’t see that anyway. What matters is how the website looks.
Most websites make heavy use of <div> and <span>, and ignore semantic HTML. In that case, you’ll need other indicators to orient yourself at. Specifically: Class names, IDs, and what attributes they have.
A first pro-tip: Try to find the smallest common denominator for your data and only access this with your XPath. Do not write absolute XPaths to try to find the correct
<div>by assuming some path from the document root to the target div. That will cause tons of headaches and make your web scraper incapable of dealing with any deviations across pages. Instead, target a div’s class names, or certain attributes that are unique to the div you want to have. If that doesn’t work, take the closest div or span element that has such a unique class or ID or attribute, and form a relative XPath from there.
Don’t try to write lengthy snakes of div#main-content div.container div.nav-wrapper a.nav-link. If you want to play around with this a bit more, have a look at document.querySelectorAll, which works just like XPath, but can be quickly used inside the browser to verify which paths give you only the elements you want.
Recently, I came across a horrific example of the extremes to which it can go if you try to write absolute XPaths: //*[@id="mount_0_0_kc"]/div/div[1]/div/div[3]/div/div/div[1]/div[1]/div[2]/div/div/div/div/div[1]/div/div/div/div[7]/div/span/div[2]/div. Don’t do this. Even if the website tries to make it hard for you to scrape it, there are better ways than this if you think a bit about the problem.
CSS-driven HTML
Another issue you will often see is CSS-driven HTML. This is not an established technical term, so no need to remember that.
What I mean is that sometimes the HTML you see is different from the HTML that is actually part of the website. It turns out that many things in HTML can be shown or hidden with CSS. There are many instances in which you may want to show or hide elements conditionally.
For example, take an accordion. An accordion is named like that because it contains several sections with a small heading of which only the heading is initially shown. Users can then click to show or hide certain sections. For you as a web scraper, this might be interesting if you are interested only in visible content.
There are three levels to CSS-driven HTML, in increasing difficulty.
The simplest case of this is the style-rule display: none. This CSS-rule will cause the HTML element to which it is applied to be hidden from view. With XPath, you should be able to quickly filter out (or select exclusively) elements with this style rule.
The same also applies to certain semantic HTML elements, such as <details>:
<details>
<summary>This heading is visible</summary>
Any contents within the "details" tag is hidden by default, except you set the "open"-attribute.
</details>
<details open>
<summary>An open by default details element</summary>
This text will be visible by default.
</details>
The <details>-tag is a semantic tag, meaning that it will only be used in instances where content needs to be conditionally visible or hidden, so it will be easier for you to deal with such elements. If you see a details tag, you know that its content will be hidden, except it also contains the attribute open.
It becomes more difficult if a hidden style is part of a CSS-class. I will get to that later, but you can specify CSS-rules either by writing them directly into the HTML-element itself (style="rule: value; rule2: value; ..."), or by applying a CSS-class which contains all of these rules. In the latter case, you can’t find out if an element is visible or hidden by using XPath. Instead, you need to realize that an element is hidden from view, and then find the corresponding CSS class.
The final evolution of CSS-driven HTML is when web designers “hide” an element by applying position: absolute; top: -10000px. What does this do? Well, it makes the position of the HTML element absolute and moves it 10,000 pixels upwards, effectively out of view. Have fun dealing with this.
In conclusion, CSS-rules can also be either semantic or non-semantic. Usually, a CSS class that hides an element will be called hidden, but there is nothing that stops a web designer from calling a class visible, even if the class causes an element to be hidden.
A second pro-tip: Usually, CSS classes are typically the ideal candidates for targeting elements. In 99% of all cases, the CSS classes will make at least some sense. Often, elements have more than one class. Many classes are used to apply some generic styling to a large amount of different elements, but a few will be unique to the element you are actually interested in. For example:
class="card card-large movie". These three classes indicate that it’s a “large” “card”, which is unspecific. But the “movie” class is likely a unique class that identifies the elements you are interested in.
(Badly) Generated HTML
The next form of CSS-driven HTML is (badly) generated HTML. As I mentioned in the introduction, any data that you will want to scrape needs to be wrapped in HTML by the server, a process that you need to reverse in the scraping process. However, depending on what software you are dealing with, that process of generating HTML is better or worse. Most websites work a lot like WordPress-pages that you may already be familiar with: If you look at the source code of such a website, it should be reasonably formatted. Now, do me a favor, visit instagram.com (or, alternatively, facebook.com) and view the source code.
Can you see the structure? No? Don’t worry, you can’t, because there is none. I will go into what this is in more detail below in the JavaScript section. But that HTML has nothing to do with the actual data. The CSS classes that Instagram uses are generated, which means they are effectively meaningless. Also, everything is wrapped in <div>-elements, and it is almost impossible to scrape that website – not only because of all the JavaScript it uses, but also because it contains no semantic elements. Sometimes, this is desired (this process is called obfuscation and Meta makes use of this to prevent web scraping of their social networks), but sometimes this is just a sign of bad web design.
In the case of Facebook, it turns out that – despite Meta’s attempts at obfuscation – you can still orient yourself at what is known as ARIA-tags. What is ARIA now?! ARIA is short for “Accessible Rich Internet Applications” and effectively defines a set of HTML attributes that make it easier for people with screen readers to navigate the app. And despite its hopes to prevent scraping of their website, Meta needs to include disabled people, so while the usual suspects are obfuscated, the screen reader attributes cannot be obfuscated. It turns out that screen readers are little web scrapers as well, and you may be able to make use of them to target the correct elements as well.
Web-Components and Shadow-DOM
Another technique that is becoming more and more popular is to design your own HTML tags. The original set of HTML tags is pretty complete, but there are always things you need for your particular use-case that aren’t part of the HTML standard. For example: Switches. It is simple to add checkboxes to your website, but if you want a switch, this is more difficult. Look at the bottom of this website: There is a three-way-toggle for the theme. HTML does not have a tag called <three-way-toggle>. Instead, I had to implement this myself. Effectively, there are three individual radio inputs, but styled in a way to make them look as if they’re just a single element.
A cleaner way of doing so is to use a technique called web-components. A web component is a JavaScript component that builds these HTML tags. What this means is that you include some JavaScript code that defines such a tag, and whenever you want to use it, you would just write <three-way-toggle>. To actually display such a toggle on a website, the web component will use what is called a “Shadow-DOM”.
A quick recap: DOM is short for Document Object Model, and it describes some data structure. When you have a three-way-toggle, what is relevant is only that there is the tag, and that it can have three states (in the case of my website: forced-light, forced-dark, and follow operating system). How it actually looks is not part of the data of the HTML, so it should not be visible in the source code. That is why it is called a “Shadow”-DOM: It is there, and it is necessary (because you do need a few elements to actually make it visible), but it doesn’t carry any additional data relevant for the HTML of the website. A Shadow-DOM is basically nothing but an HTML-document embedded in a single tag for decorative purposes.
As a web scraper, the only thing you need to know is that you don’t have to care about Shadow-DOMs. There are ways of extracting that, but it should not contain any relevant information for you. But it helps to know what its purpose is.
Web-components already show a lot for why it is impossible to understand modern websites without also understanding CSS and JavaScript, because all three technologies are deeply intertwined. So let’s quickly move to the next technology.
CSS
As mentioned in the introduction, CSS, or Cascading Style Sheets, are exclusively used to style elements. CSS does not add or remove any data from the HTML, but it can be helpful in scraping. There are three parts of CSS that you need to know: Style attributes, IDs and class selectors.
The most basic way is to add a “style”-attribute to the HTML-element in question and list those styles you want:
<span style="color: red; text-decoration: underline;">This text is red and underlined</span>
However, with more and more rules, this can quickly become unwieldy. This is why you will more often see class names. Using CSS classes allows you to separate the actual rules from the HTML code, which makes it more legible:
<style>
.red-text {
color: red;
text-decoration: underline;
}
</style>
<span class="red-text">This text is red and underlined</span>
Since you have to give that class a name, oftentimes the class name will tell you something about what it does, in this example: making text red. Sometimes you may come across HTML like this:
<a class="btn btn-primary btn-small" href="www.example.com">A link</a>
With the class-names you can say a lot about this element: It is a link (<a>) that should resemble a button btn. More specifically, a small primary button.
IDs are functionally the same as classes, with the only difference being that IDs are only used once per page. The button links above are all part of the class of button links, but a main container, for example, is unique on a website.
CSS classes and IDs are a fundamental part of XPath that you should already be familiar with if you’ve done some web scraping, but besides that, you don’t need to know too much. As mentioned above, the only actually important CSS part that you’ll need to know is how elements are hidden – and even this only in some cases.
JavaScript
Now to the final web technology you need to understand to be successful in web scraping: JavaScript. While HTML is required to display content on a website and CSS is required to style it, JavaScript is used to alter any and everything on a website. When JavaScript is in play, you cannot trust anything on a website: Every HTML element could disappear in an instant, new elements can appear, and CSS classes and IDs can be added and removed on a whim.
JavaScript is not required for a website, but is basically everywhere. Websites use it in all quantities, and while it often just enhances a website, some websites are implemented as so-called single-page applications (SPA) in which case everything is JavaScript.
In general, there are three “levels” of the usage of JavaScript. “Progressive” use when it is only used cosmetically. Then, there is “lazy loading”; commonly used to reload parts of a website without a full reload. Finally, there are full-scale “Progressive Web Applications” (PWA) or “Single Page Applications” (SPA) where everything is handled by JavaScript.
Progressive Web Design
Back in the days when JavaScript was not yet as powerful as it is today, it was typically used to enhance a website. JavaScript was sparsely used to dynamically animate content or fetch a small list of autocomplete-values, such as a list of U.S. states for web-forms. It was also used to validate form entries, e.g., to ensure that you entered a valid phone number.
This is called progressive web design: When a website is made “progressively” better with the use of dynamic JavaScript. Usually, you don’t have to worry about this. When you scrape a website, JavaScript is not executed, so no changes are applied to the HTML code for which JavaScript code is responsible. When the changes from JavaScript are purely cosmetic, this isn’t problematic.
Lazy-Loading
Sometimes, the amount of data to load is very large. In that case, many websites make use of a technique called pagination. Pagination ensures that only a few hundred rows of the data are fetched and displayed. This ensures that each individual page loads reasonably fast, while allowing users to browse the entire dataset. For web-scraping purposes, this is somewhat annoying, but nothing to worry about.
However, there is a JavaScript-equivalent to pagination that works a bit fancier: lazy-loading. Lazy-loading is effectively the same as pagination, but can be implemented by way of “endless scrolling” where contents towards the end of a list is dynamically fetched as the user scrolls downwards.
For web-scraping purposes, this is problematic, since this means that we have to execute JavaScript in order to actually fetch the data. The surroundings of the website are still present in the HTML, but the actual content we are interested in is loaded dynamically with JavaScript. However, this data comes from a private API. More on that below.
Single-Page Applications (SPA) & Progressive Web Apps (PWA)
The peak progressiveness is reached with Single-Page Applications (SPA) and Progressive Web Apps (PWA). From a web-scraping perspective, the differences between both don’t matter, but remember the Instagram-example from above: Instagram is a PWA. The content that you receive when you simply download the HTML is essentially just the <body>-tag. Everything inside it will be loaded dynamically by the JavaScript code. This means: Usual web scrapers won’t be able to scrape anything, because they don’t execute any JavaScript.
In that case, without help of Browser drivers such as Selenium or Puppeteer, you won’t be able to extract a single bit of data. The benefits for a business are that nobody will be able to properly scrape their data without paying for (as we know since the Twitter-apocalypse sometimes hefty) API access fees. The benefits for the users, on the other hand, are that pages load considerably faster because only the actual data has to be loaded, and not the HTML that wraps the data. This is why sometimes a web scraper will tell you it couldn’t find an element that you can clearly see when you inspect a website: because it has been rendered by JavaScript, and it was not part of the original payload that the server sent.
Excursus: Server-Side-Rendering (SSR)
There is somewhat of a counter-trend, however: server-side rendering, or SSR. SSR means that the task of wrapping all the data into HTML tags is split up between the server and your browser. Elements that are static will be rendered by the server and included in the original payload when you visit a website. These elements will be visible to your web scraper. Only parts of the HTML will be rendered dynamically by JavaScript.
The reason is that sometimes the amount of rendering that your browser has to do when everything is dynamically populated is so large that you would notice a slowdown when you load a website. Instead, elements that don’t have to be dynamic will be rendered by the server and likely cached for other users, too. The process of some JavaScript code “taking over” a website in SSR is called “hydration”, since it resembles the process of hydrating dehydrated mashed potato powder when you cook.
For your web scraping purposes, however, this likely won’t help you since the most crucial parts of the data you need – the Instagram feed, the Facebook timeline, and the Twitter home feed – are still loaded dynamically.
There is one benefit, however: Even JavaScript has to retrieve the data from somewhere. If the data is not contained in the HTML code that the server sends you when you load a website initially, it needs to be fetched from somewhere. In other words, even SPAs and PWAs require a server that sends that data if requested.
Using Private APIs
This leads me to a potential remedy for still getting to the data even if it’s an SPA or PWA: There must be some API that the JavaScript code can use to fetch the precious data. The only difference to a regular API is that it’s “private”, i.e., not intended for public use. Every SPA or PWA is powered by some API that holds the data. In essence: even if you’re facing an SPA/PWA, you can still perform web scraping, you only have to figure out how to use that private API. Web scraping either requires to load HTML code and wrestling the data out of it, or contacting an API – which means that in the end you probably don’t need to touch any JavaScript.
There are two issues, though. First, it is a “private” API because it is exclusively intended to be used in conjunction with the web app that loads the content. Usually, there are terms of service that forbid the use of this API explicitly or implicitly. If the data is intended for public usage and downloading the data is encouraged, then things are more gray. In such a case, using a private API might be an option. However – and this is the second issue – do keep in mind that nobody likes to see some automated script fetching Gigabytes of data from a server that was intended for some human to slowly click element after element. Therefore, should you ever get into the situation of actually using such a private API, keep in mind that you’re not the only one accessing that API, and that others may, too, need the data. If you mindlessly download hundreds of data points every second, this can make the web server crash. If that happens, you have accidentally successfully run a Denial-of-Service (DoS) attack and could be legally liable.
I am not a lawyer, so I cannot give you any advice here, except: Don’t, unless you have explicit permission from the website owners to use such a private API. I am only showing you the tool, not how to wield it.
Conclusion
This concludes our short journey through the horrors of web design. There is much more to it, but entire books have been written on web design and I do not want to be repetitive. If you want to excel at web scraping, you need to understand the web design behind it. The ideal situation for you would be to learn web design directly, since then you’ll have a much better grasp of the thought processes behind websites. But you probably don’t have to scrape data so often, and thus I don’t think it would be the best use of your time.
By now you should have a good idea about what the various structures and the “spaghetti code” you sometimes see on websites are all about. Much of the contents of this article has been structured based on questions I’ve received from students over the years, and I hope that it helps you, too. If you have any more questions in this regard, of course feel free to ping me on social media or via mail!
Some websites don’t even manage to do that, and I have a pet peeve for such websites. I have a bookmark folder named “Violent Web Design” where I collect the worst offenders I stumble upon during my research. For many years during my M.A. studies, the pole position was held by the Indian government, but unfortunately (or fortunately?) they have revised their websites since, and thus I had to demote them to “Acceptable Web Design”. If you have recommendations, please keep them coming! ↩